学习了一下scrapy爬虫的部署,记录一下过程。
一、服务器端
1 安装包
1 | |
2 修改scrapyd配置文件
2.1 首先找包的安装路径
1 | |
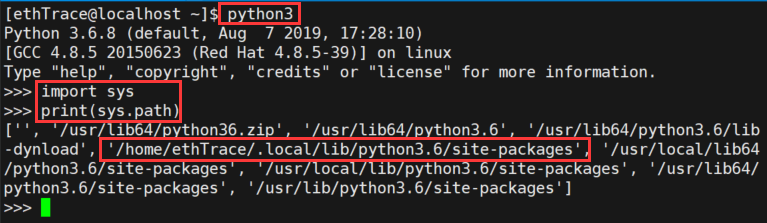
image-20201116153610363
2.2 修改scrapyd的配置文件
1 | |
将bind_address改为0.0.0.0
3 启动scrapyd
1 | |
4 验证启动是否成功
在这之前需要开启服务器的6800端口。如果是自己买的服务器,不光要检查防火墙端口是否开放,还需登录购买服务器的官网,检查安全组是否开放6800端口。
在本地浏览器输入http://服务器ip地址:6800,如下图所示,则表示启动成功
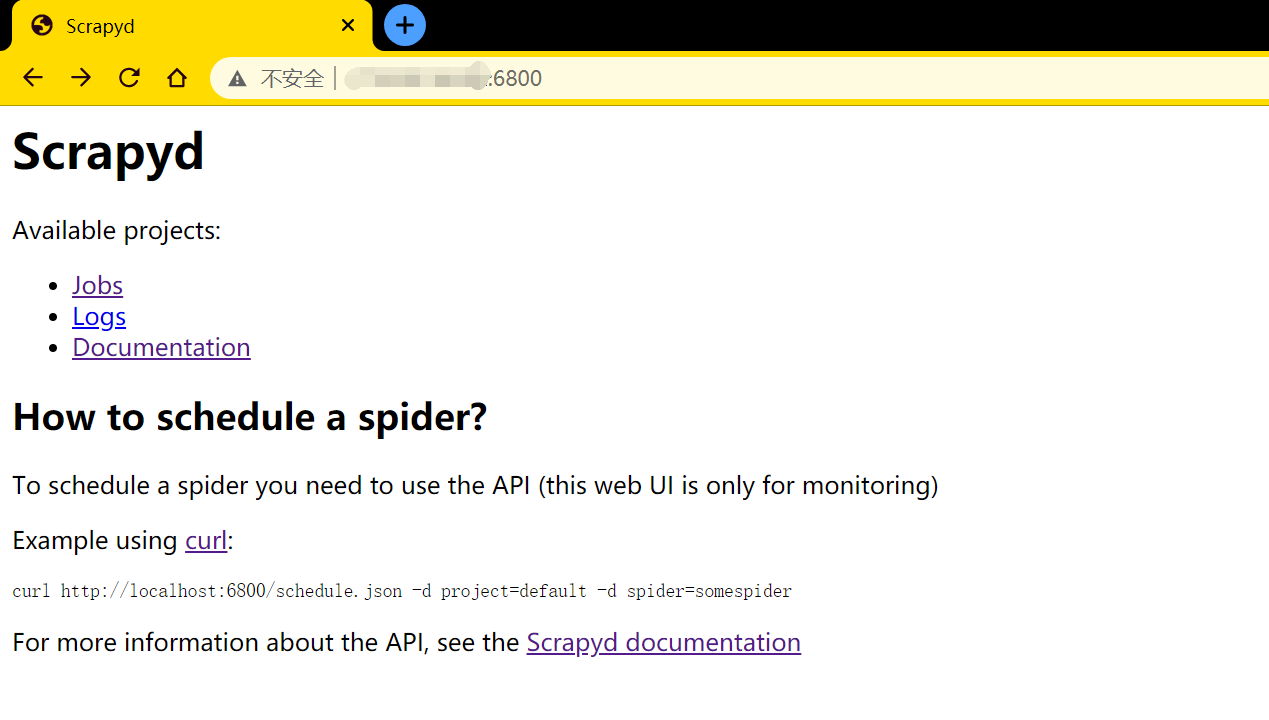
image-20201116154829745
二、本地
1 安装包
1.1 安装scrapy-client
==注意==:安装scrapy-client,win10系统如果直接用pip安装可能会发生不能识别scrapy-deploy命令的错误。所以建议直接通过下载github源码安装。
源码地址,下载后解压,在文件夹下执行如下命令:
1 | |
若已经用pip安装了的,先卸载Scrapyd-client
1 | |
1.2 安装curl
下载地址,win10_64位下载如下版本。
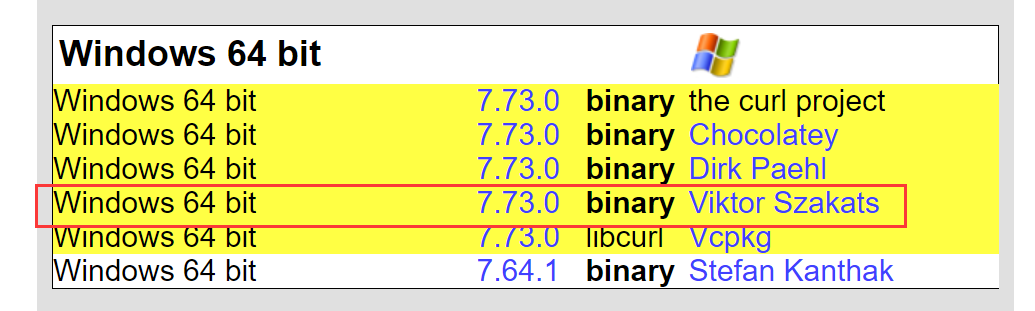
image-20201116161250262
添加环境变量
CURL_HOME:为解压后的文件夹根目录
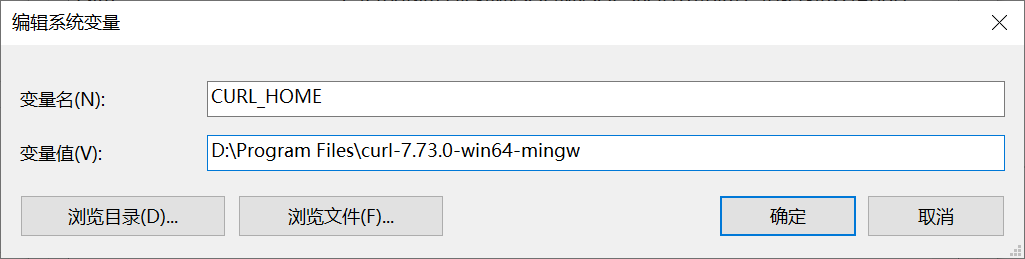
image-20201116161520511
Path中添加两个地址
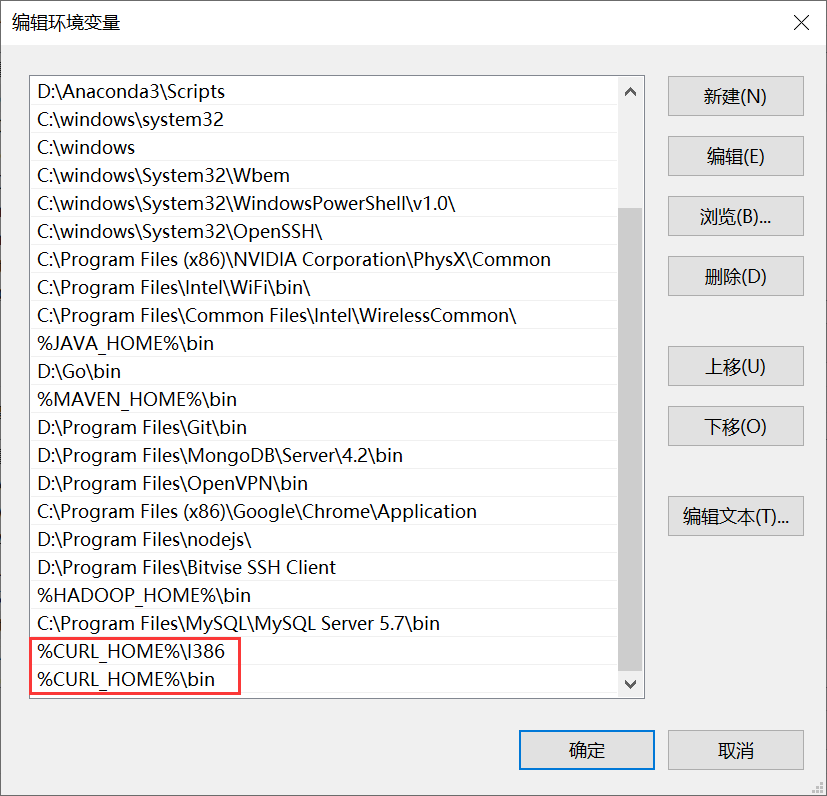
image-20201116161617776
测试是否安装成功,在powershell中会出错,推荐用cmd。
1 | |
2 修改项目文件夹下的scrapy.cfg文件
1 | |
3 部署
3.1 打包
在项目根目录下启用cmd,执行如下命令。一定要在CMD中运行命令,powershell中会出错
1 | |
3.2 上传
1 | |

image-20201115181731049
服务器端会出现两个文件夹,表示上传完成
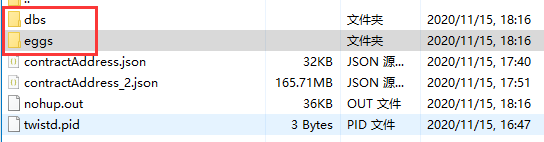
image-20201115181924994
3.3 检查服务器运行状态
1 | |
3个0,表示没用等待和运行以及完成的爬虫任务。
{% image https://i.loli.net/2020/11/16/AiNOaBM8lxG5e7F.png 'image-20201116162152531' '' %}4 启动爬虫
1 | |
注意:spider后面跟的是文件名,不是文件夹名。
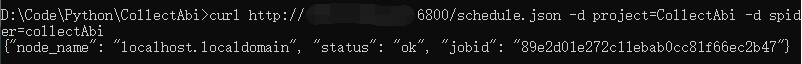
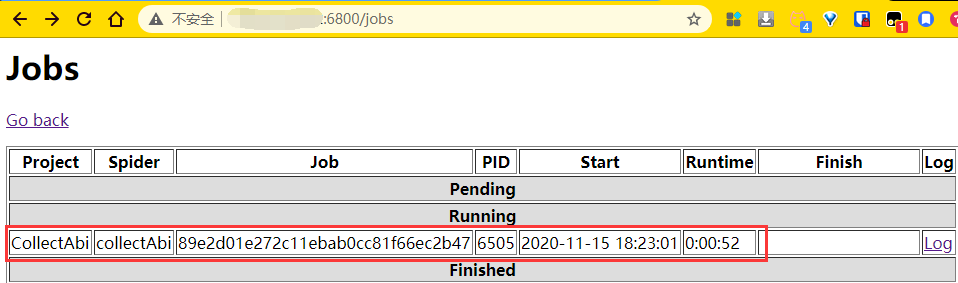
image-20201115182328977
5 停止爬虫
1 | |
