找了学长内推了字节跳动懂车帝的后端岗位,这也是作者本人的第一次面试,有纪念意义,所以记录一下过程。
懂车帝后端主要用Go和python语言,因此相对来说就会少问一些java方面的知识。
面试的平台是在牛客网上,上来先做了一个简短的自我介绍,然后就直接开始问问题了。
问题1、从长度未知的链表中随机取出一个数。 首先,需要说明这是一个经典的问题,需要用蓄水池抽样算法。但是本人当时并不知道这个算法。因此想出了两个方案,但是面试官都说不对,因此最后在面试官的提示下需要回去看看蓄水池算法。
错误方法1:先获取链表的长度,然后取链表长度的随机数,再取相应随机数位置的数。
面试官说不能获取链表的长度。
错误方法2:先生成一个随机数,然后取随机数位置上的链表上的数。会出现两种情况,一种是数到相应的位置上有数,直接取。第二种情况,向后遍历链表直到链表尾,发现随机数大于链表长度,这时候用随机数对链表长度取余数。取余数位置上的数。
面试官说还是需要获取到链表的长度。WTF?向后遍历到链表的尾部的同时就能够记录到链表的长度的啊。
正确答案:蓄水池取水算法
前提: 给定一个数据流,数据流长度N很大,且N直到处理完所有数据之前都不可知,请问如何在只遍历一遍数据(O(N))的情况下,能够随机选取出m个不重复的数据。(这里面试官没有说出来只能够遍历一次链表)。本题面试官提出的是取一个数据,因此把m设置为1即可。
算法思路大致如下:
如果接收的数据量小于m,则依次放入蓄水池。 当遍历到第i个数据时,i >= m,在[0, i]范围内取以随机数d,若d的落在[0, m-1]范围内,则用这第i个数据替换蓄水池中的第d个数据。 重复步骤2。 算法随机性的证明:
第i个数据最后能够留在蓄水池中的概率=第i个数据进入过蓄水池的概率*第i个数据不被替换的概率 (第i+1到第N次处理数据都不会被替换)。
当i<=m时,数据直接放进蓄水池,所以第i个数据进入过蓄水池的概率=1 。 当i>m时,在[1,i]内选取随机数d,如果d<=m,则使用第i个数据替换蓄水池中第d个数据,因此第i个数据进入蓄水池的概率=m/i 。 当i<=m时,程序从接收到第m+1个数据时开始执行替换操作,第m+1次处理会替换池中数据的为m/(m+1),会替换掉第i个数据的概率为1/m,则第m+1次处理替换掉第i个数据的概率为(m/(m+1))*(1/m)=1/(m+1),不被替换的概率为1-1/(m+1)=m/(m+1)。依次,第m+2次处理不替换掉第i个数据概率为(m+1)/(m+2)…第N次处理不替换掉第i个数据的概率为(N-1)/N。所以,之后第i个数据不被替换的概率=m/(m+1)*(m+1)/(m+2)*...*(N-1)/N=m/N。(这里如果m==1,表示只取一个数据,因此概率为1/N ) 当i>m时,程序从接收到第i+1个数据时开始有可能替换第i个数据。则参考上述第3点,之后第i个数据不被替换的概率=i/N 。 结合第1点和第3点可知,当i<=m时,第i个接收到的数据最后留在蓄水池中的概率=1*m/N=m/N。结合第2点和第4点可知,当i>m时,第i个接收到的数据留在蓄水池中的概率=m/i*i/N=m/N。综上可知,每个数据最后被选中留在蓄水池中的概率为m/N 。 这个算法建立在统计学基础上,很巧妙地获得了"m/N"这个概率。
问题2、写一个斐波那契数列。给n求n位置上的值 0、1、1、2、3、5……
1 2 3 4 5 6 def fib (n) :if n == 0 :return 0 if n == 1 :return 1 return fib(n-1 )+fib(n-2 )
问题3、斐波那契数列递归算法的时间空间复杂度,以及如何优化 时间复杂度O(n)
空间复杂度O(n)
优化采用自底向下的动态规划算法。
1 2 3 4 5 def fib (n) :0 ,1 ]for i in range(2 ,n+1 ):-1 ]+res[-2 ])return res[n]
这种算法需要空间空间复杂度为O(n),可以再优化为常数级别。
1 2 3 4 5 6 7 8 def fib (n) :0 1 if n == 0 :return num1for i in range(2 ,n+1 ):return num2
说起来惭愧,这是《剑指offer》上的原题,面试之前作者并没有读过,当时又非常紧张,没有写出来这道题。面完试感觉这道题是easy的。
问题4.操作系统什么时候会从用户态进入到内核态 内核态主要涉及到一些特权指令的操作。发生系统调用时会从用户态转移到内核态。
系统调用:
问题5.Tcp拥塞控制 慢开始: 指数增长就是将拥塞窗口cwnd设置为1,没经过一个RTT,cwnd加倍,指数增长。知道到达满开始门限阈值采用拥塞避免算法。
拥塞避免: 线性zeng’zhang每经过一个RTT就增加一个MSS大小。知道出现第一次超时(网络拥塞),就将慢开始门限设置为此时拥塞窗口值的一半。然后把cwnd重置为1。执行慢开始算法。
快重传: 当发送方接收到3个冗余ACK时,就认为确认的报文后面的报文段丢失了。并立即对缺失的报文段重传。
快恢复: 就是发生冗余ACK时间时候,将慢开始门限设置为当前的一半,然后将cwnd设置慢开始门限值,开始拥塞避免算法。
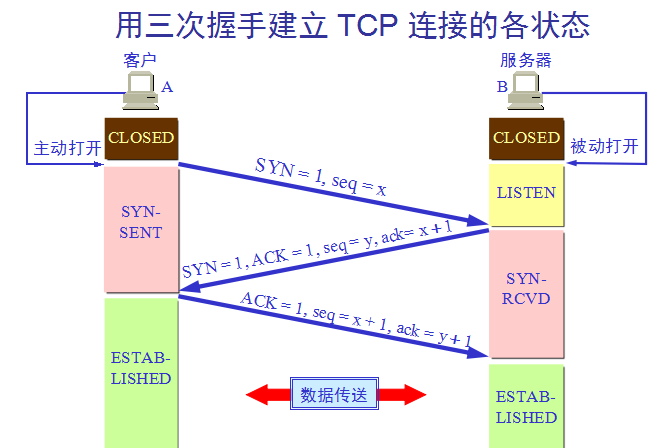
问题6.进程通信方式 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。 问题7.Tcp连接三次握手,为什么不是两次 tcp三次握手
第一次握手: 客户机向服务器发送连接请求报文 。
第二次握手: 服务器的TCP收到连接请求报文之后,同意链接,向客户机发回确认,为TCP连接分配TCP缓存和变量。
第三次握手: 客户机收到确认报文,向服务器发送确认报文为连接分配缓存和变量。
为什么不是两次?
防止客户端失效的连接请求报文段突然又传到服务器
例如以下情况如果使用两次握手:
如果客户端向服务器发送第一次连接请求在网络节点上滞留了,没有收到服务器的确认,于是又重新发送了一次连接请求 服务器收到客户端的第二次请求发送确认,则连接建立完成 服务器客户端进行数据传输,传输完成断开连接。 此时,在网络上滞留的客户端第一次连接请求到达服务器,服务器发送确认连接但是客户端实际上并没有发送请求,因此不会理睬服务器发送的请求。但是服务器认为连接已完成,并等待客户端进行数据传输。这样会造成资源的浪费 如果采用三次握手的话:
滞留在网络上的客户端第一次请求到达服务器之后,服务器发送确认,但实际上服务器并没有发送请求,因此不会理睬服务器的确认,故不会发送确认,服务器等不到客户端的确认则连接建立失败。这样就防止了客户端失效的连接请求报文段突然又传到服务器 总结 这是作者本人的第一次面试,面试的时候很紧张。面试官出了编程题马上就上手去写,没有思考的过程,也没有去问具体的一些要求。导致越写越慌,到最后连斐波那契数列这样的基础题,也没有写出来。基础知识也很不牢靠,一些简单的问题,也没有答上来。
在面试后在网上找了一些《剑指offer》的资料,发现前几章很有帮助,其中比较重要的一点就是,拿到面试题先思考,不理解需求的问,想清楚了之后再具体的写代码。
一些面试题答案的参考文献:
https://www.jianshu.com/p/7a9ea6ece2af
https://blog.csdn.net/zhaohong_bo/article/details/89552188
https://blog.csdn.net/qq_41727218/article/details/87881235
]]>