在菜鸟教程中学了MongoDB,做此笔记以记录。
一、MongoDB安装
1.下载
官方下载地址:https://www.mongodb.com/download-center/community
快速下载地址:http://dl.mongodb.org/dl/win32/x86_64
2.安装
点击custom可以修改安装目录,另外取消勾选Install MongoDB Compass选项。此为图形界面管理工具。
3.配置
将bin文件夹配置到PATH的环境变量中。
在data文件夹下手动创建db和log
在log文件夹下创建mongodb.log
在安装文件夹下新建mongo.config
文件中写入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#数据文件,路径必须是你自己的电脑的对应路径
dbpath=D:\Program Files\MongoDB\Server\4.2\data\db
#日志文件
logpath=D:\Program Files\MongoDB\Server\4.2\data\log\mongodb.log
#错误日志采用追加模式,配置这个选项后mongodb的日志会追加到现有的日志文件,而不是从新创建一个新文件
logappend=true
#启用日志文件,默认启用
journal=true
#这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=true
#端口号 默认为27017
port=27017
点击mongod.exe,如果闪一下退出,说明安装正常。进入测试地址localhost:27017。

进入bin文件夹,使用如下命令:
1
mongod --config D:\Program Files\MongoDB\Server\4.2\mongo.config --install --serviceName "MongoDB"右键我的电脑,管理查看mongoDB服务是否自动开启。
Warning:
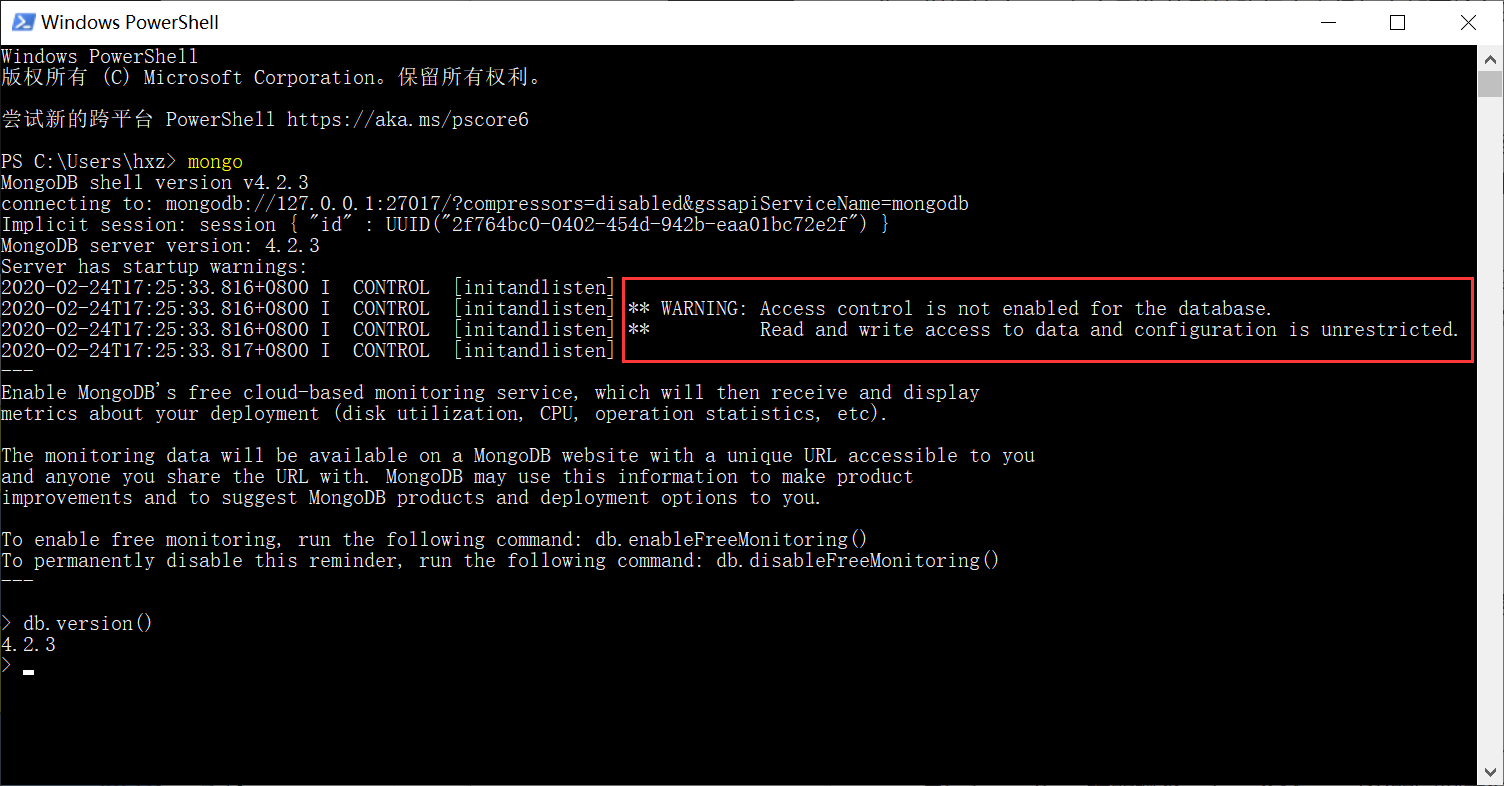
原因:新版本的MongDB增加了安全性设计,推荐用户创建使用数据库时进行验证。如果用户想建立简单连接,则会提示警示信息。
解决方案:
创建管理员并设置密码
1 | |
二、Robo 3T安装
1.下载
官方下载地址:https://robomongo.org/download
2.建立连接
点击Create,
{% image https://i.loli.net/2020/06/05/MvmSsP2EQZG3huK.png 'QQ截图20200224202820' '' %}修改连接名,save
{% image https://i.loli.net/2020/06/05/j5spKWLImNF6ic9.png 'QQ截图20200224202902' '' %}三、基本概念
1.概念
- MongoDB有着与您熟知的‘数据库’(database,对于Oracle就是‘schema’)一样的概念。在一个MongoDB的实例中您有若干个数据库或者一个也没有,不过这里的每一个数据库都是高层次的容器,用来储存其他的所有数据。
- 一个数据库可以有若干‘集合’(collection),或者一个也没有。集合和传统概念中的‘表’有着足够多的共同点,所以您大可认为这两者是一样的东西。
- 集合由若干‘文档’(document)组成,也可以为空。类似的,可以认为这里的文档就是‘行’。
- 文档又由一个或者更多个‘域’(field)组成,您猜的没错,域就像是‘列’。
- ‘索引’(index)在MongoDB中的意义就如同索引在RDBMS中一样。
- ‘游标’(cursor)和以上5个概念不同,它很重要但是却常常被忽略,有鉴于此我认为应该进行专门讨论。关于游标有一点很重要,就是每当向MongoDB索要数据时,它总是返回一个游标。基于游标我们可以作诸如计数或是直接跳过之类的操作,而不需要真正去读数据。
小结一下,MongoDB由‘数据库’组成,数据库由‘集合’组成,集合由‘文档’组成。‘域’组成了文档,集合可以被‘索引’,从而提高了查找和排序的性能。最后,我们从MongoDB读取数据的时候是通过‘游标’进行的,除非需要,游标不会真正去作读的操作。
2._id生成规则
MongoDB的文档必须有一个_id键。
目的是为了确认在集合里的每个文档都能被唯一标识。
ObjectId 是 _id 的默认类型。
ObjectId 采用12字节的存储空间,每个字节两位16进制数字,是一个24位的字符串。
12位生成规则:
[0,1,2,3] [4,5,6] [7,8] [9,10,11]
时间戳 |机器码 |PID |计数器
- 前四字节是时间戳,可以提供秒级别的唯一性。
- 接下来三字节是所在主机的唯一标识符,通常是机器主机名的散列值。
- 接下来两字节是产生ObjectId的PID,确保同一台机器上并发产生的ObjectId是唯一的。
前九字节保证了同一秒钟不同机器的不同进程产生的ObjectId时唯一的。
- 最后三字节是自增计数器,确保相同进程同一秒钟产生的ObjectId是唯一的。
四、语法格式
1.创建数据库
1 | |
如果数据库不存在,则创建。否则切换到指定数据库
2.查看所有数据库(无数据则不显示)
1 | |
3.删库(先use,再drop)
1 | |
4.创建集合(表)
1 | |
- name:要创建的集合名字
- options:可选参数
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | (可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值,以千字节计(KB)。 如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
1 | |
5.查看集合
1 | |
6.删除集合
1 | |
7.插入文档(一条记录)
1 | |
也可以将数据定义为一个变量,然后插入:
1 | |
8.查看已插入文档
1 | |
9.更新文档
1 | |
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc…)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
save() 方法通过传入的文档来替换已有文档。语法格式如下:
1 | |
- document : 文档数据。
- writeConcern :可选,抛出异常的级别。
1 | |
10.删除文档
1 | |
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
- writeConcern :(可选)抛出异常的级别。
11.查询文档
1 | |
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
1 | |
11.1 ==比较操作符==
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {:} | db.col.find({"by":"菜鸟教程"}).pretty() |
where by = '菜鸟教程' |
| 小于 | {:{$lt:}} | db.col.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
| 小于等于 | {:{$lte:}} | db.col.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
| 大于 | {:{$gt:}} | db.col.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
| 大于等于 | {:{$gte:}} | db.col.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
| 不等于 | {:{$ne:}} | db.col.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
11.2 AND比较条件
多条件间以逗号隔开
1 | |
11.3 OR比较条件
1 | |
11.4 AND 和 OR 联合使用
1 | |
11.5 使用 (<) 和 (>) 查询
1 | |
11.6 $type操作符
1 | |
12.Limit与Skip方法
1 | |
==db.col.find({},{“title”:1,_id:0}).limit(2)==
1 | |
13.排序
sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
1 | |
14.创建索引
1 | |
Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
createIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
15.聚合
1 | |
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$sum : “$likes”}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$avg : “$likes”}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$min : “$likes”}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$max : “$likes”}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : “$by_user”, url : {$push: “$url”}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : “$by_user”, url : {$addToSet : “$url”}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : “$by_user”, first_url : {$first : “$url”}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : “$by_user”, last_url : {$last : “$url”}}}]) |
16.管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
1 | |
这样的话结果中就只还有_id,tilte和author三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
1 | |
五、维护
1.副本集?
2.分片集?
3.备份(mongodump)与恢复(mongorestore)
备份mongodump
1 | |
-h:
MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d:
需要备份的数据库实例,例如:test
-o:
备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
恢复mongorestore
1 | |
–host <:port>, -h <:port>:
MongoDB所在服务器地址,默认为: localhost:27017
–db , -d :
需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
–drop:
恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
: mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。
你不能同时指定
和 –dir 选项,–dir也可以设置备份目录。 –dir:
指定备份的目录
你不能同时指定
和 –dir 选项。
4.监控
mongostat会间隔固定时间获取mongodb的当前运行状态,并输出。
1 | |
mongotop提供了一个方法,用来跟踪一个MongoDB的实例,查看哪些大量的时间花费在读取和写入数据。 mongotop提供每个集合的水平的统计数据。默认情况下,mongotop返回值的每一秒。
1 | |
5.Mongodb to Json
1 | |
--authenticationDatabase admin不加这个参数会出现错误。
